
Latest News
-
Combining Clinical Embeddings with Multi-Omic Features for Improved Patient Classification and Interpretability in Parkinsons Disease
Barry Ryan, Chaeeun Lee, Riccardo Marioni, Pasquale Minervini, T. Ian Simpson
In this work we demonstrate how integration of Large Language Model (LLM)-derived clinical text embeddings from the MDS-UPDRS questionnaire with molecular genomics data can enhance patient classification and interpretability in Parkinsons Disease. By combining genomic modalities encoded using an interpretable biological architecture with a patient similarity network constructed from clinical text embeddings, we leverage clinical and genomic information to provide a robust, interpretable model for disease classification and molecular insights. This work demonstrates that the combination of clinical text embeddings with genomic features is critical for classification and interpretation.
LLM text embeddings not only increase classification accuracy but also enable interpretable genomic analysis, revealing molecular signatures associated with PD progression. Using this framework, we were able to replicate the association of MAPK in PD in a heterogenous cohort from the Parkinsons Progression Markers Initiative.
For more information find the preprint to our paper online here
-
The significance of molecular heterogeneity in breast cancer batch correction and dataset integration
Nicholas Moir, Dominic Pearce, Simon Langdon, T. Ian Simpson
Breast cancer research benefits from a substantial collection of gene expression datasets that are commonly integrated to increase analytical power. Gene expression batch effects arising between experimental batches, where signal differences confound true biological variation, must be addressed when integrating datasets and several approaches exist to address these technical differences. In this work we demonstrate that popular batch correction techniques can significantly distort key biomarker expression signals. Through the implementation of ComBat batch correction and evaluation of integrated expression values, we profile the extent of these distortions and consider an additional mitigatory batch correction step.
We demonstrate that leveraging a priori knowledge of sample molecular subtype classification can optimally remove batch effect distortion while preserving key biomarker expression variation and transcriptional legitimacy. To the best of our knowledge, this study presents the first analysis of the interplay between dataset molecular composition and the concomitant robustness of integrated, batch-corrected biological expression signal.
For more information find the preprint to our paper online here
-
An Integrative Network Approach for Longitudinal Stratification in Parkinson's Disease
Barry Ryan , Riccardo Marioni and T. Ian Simpson
Parkinson’s Disease (PD) is a neurodegenerative disorder characterized by motor symptoms resulting from the loss of dopamine-producing neurons in the brain. Currently, there is no cure for the disease which is in part due to the heterogeneity in patient symptoms, trajectories and manifestations. There is a known genetic component of PD and genomic datasets have helped to uncover some aspects of the disease. Understanding the longitudinal variability of PD is essential as it has been theorised that there are different triggers and underlying disease mechanisms at different points during disease progression. In this paper, we perform longitudinal and cross-sectional experiments to identify which data modalities or combinations of modalities are informative at different time points. We use clinical, genomic, and proteomic data from the Parkinson’s Progressive Markers Initiative (PPMI). We validate the importance of flexible data integration by highlighting the varying combinations of data modalities for optimal stratification at different disease stages in idiopathic PD. We show there is a shared signal in the DNAm signatures of participants with a mutation in a causal gene of PD and participants with idiopathic PD. We also show that integration of SNP and DNAm data modalities has potential for use as an early diagnostic tool for individuals with a genetic cause of PD.
MOGDx is a flexible tool to integrate multiple omic measures and perform classification tasks. This approach uses a network taxonomy to combine patient similarity matrices into a single network and perform node classification using a Graph Convolutional Network. It is a preferred tool to perform analysis on the PPMI dataset due to its flexibility. It can integrate any number of modalities, whilst simultaneously allowing for the retention of the maximum number of patients possible, in contrast to other existing methodologies. See our preprint on MOGDx for more information here
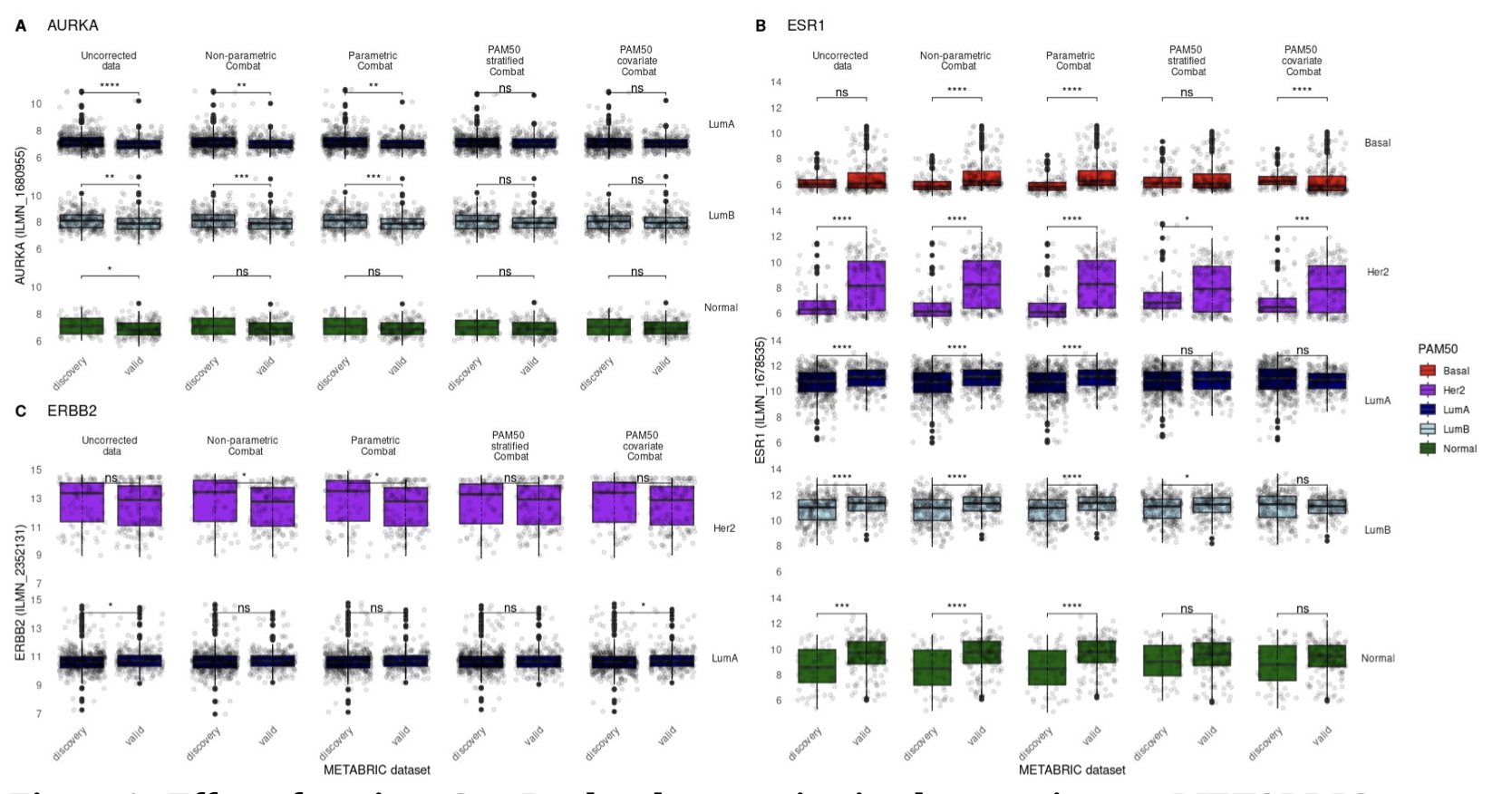
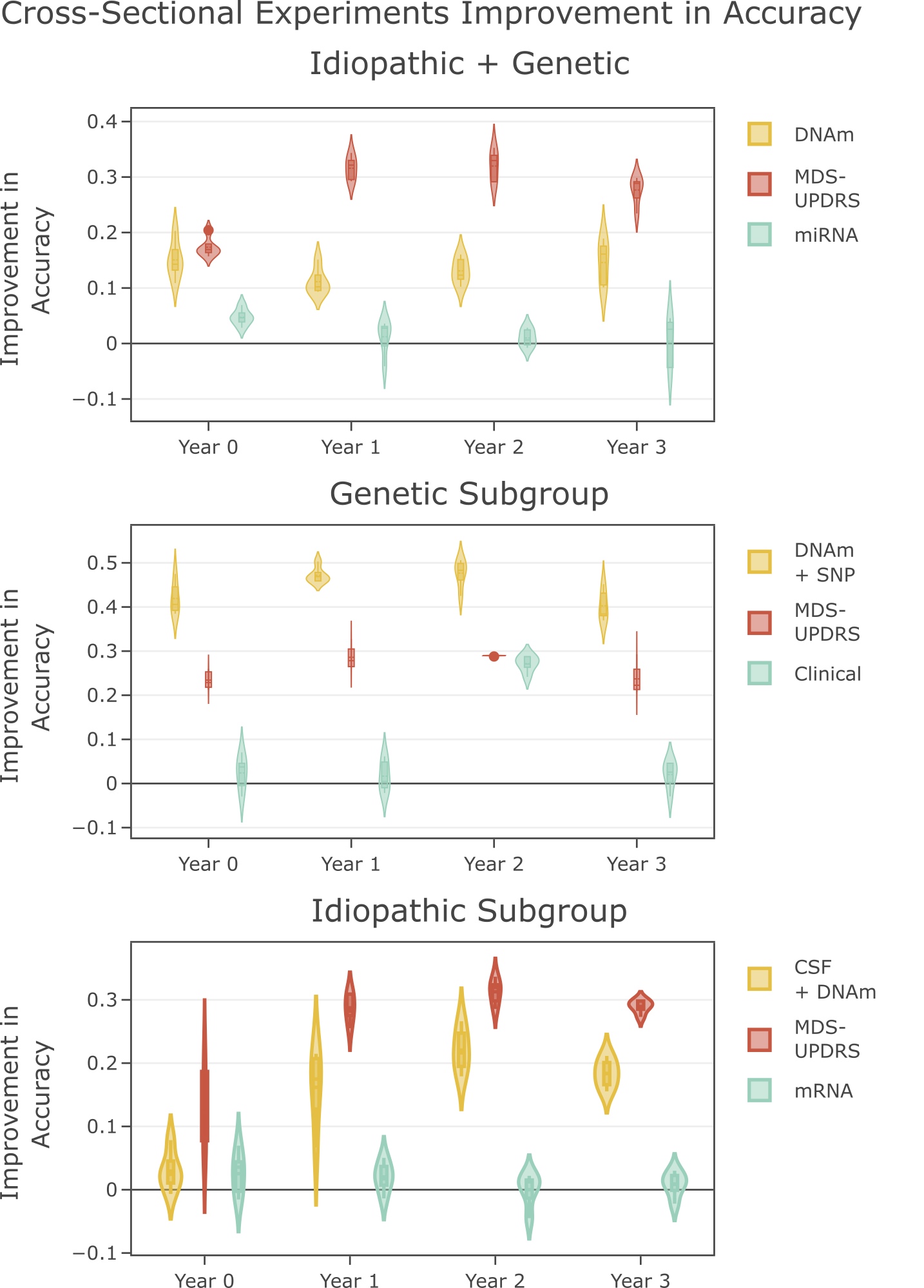
In this paper, we look at two disease subgroups: those who have a mutation in a casaul gene for PD, labelled Genetic and those who have no known genetic cause or sporadic onset, labelled Idiopathic. Using MOGDx, we have tested all available combinations of genomic data from the PPMI dataset. We highlight the performance of the best performing modalities in the figure on the right by comparing it to the worst performing modality and a baseline clinical assessment modality called the MDS-UPDRS. We obtain strongest performance when classifying in the subgroup who have a mutation in a casaul gene. We found that no single modality or combination of modality achieved optimal performance at every time point in the idiopathic subgroup, highlighting the importance of flexible modality integration. We also found that worst performance is achieved when the two subgroups are considered jointly. DNAm was predicitve for all experiments at almost every timepoint, indicating the presence of an epigenetic modification between individuals with PD and those without, regardless of subgroup.
Finally, we found that a combination of SNP and DNAm achieved excellent stratification accuracy in the genetic subgroup at all time points. Optimal performance was observed by a model trained at year 3, the latest time point available in the PPMI dataset. Our results show that this combination of modalities could be used as an early diagnostic tool and such a tool should be trained using PD patients who have progressed to a later disease stage.
For more information find the preprint to our paper online here
-
Multi-Omic Graph Diagnosis (MOGDx) : A data integration tool to perform classification tasks for heterogenous diseases
Barry Ryan , Riccardo Marioni and T. Ian Simpson
Heterogeneity in human diseases presents challenges in diagnosis and treatments due to the broad range of manifestations and symptoms. With the rapid development of labelled multi-omic data, integrative machine learning methods have achieved breakthroughs in treatments by redefining these diseases at a more granular level. These approaches often have limitations in scalability, oversimplification, and handling of missing data. In this study, we introduce Multi-Omic Graph Diagnosis (MOGDx), a flexible command line tool for the integration of multi-omic data to perform classification tasks for heterogeneous diseases.
MOGDx incorporates a network taxonomy for data integration and utilises a graph neural network architecture for classification. Networks con be easily integrated, can readily handle missing data, and have been used in a wide variety of biomedical applications in the unsupervised setting. Graph Neural Networks (GNN) have shown powerful classification performance on several benchmark network datasets. The use of GNN’s in a supervised setting for disease classification is a promising avenue to redefine heterogenous diseases.
The performance of MOGDx was benchmarked on three distinct datasets from The Cancer Genome Atlas (TCGA) for breast invasive carcinoma, kidney cancer, and low grade glioma. MOGDx demonstrated state-of-the-art performance and an ability to identify relevant multi-omic markers in each task. It did so while integrating more genomic measures with greater patient coverage compared to other network integrative methods. MOGDx is available to download from Github.
Find the full paper in the journal Bioinformatics
-
Multi-Omic Graph Diagnosis (MOGDx) : A data integration tool to perform classification tasks for heterogenous diseases
Barry Ryan , Riccardo Marioni and T. Ian Simpson
Heterogeneity in human diseases presents challenges in diagnosis and treatments due to the broad range of manifestations and symptoms. With the rapid development of labelled multi-omic data, integrative machine learning methods have achieved breakthroughs in treatments by redefining these diseases at a more granular level. These approaches often have limitations in scalability, oversimplification, and handling of missing data. In this study, we introduce Multi-Omic Graph Diagnosis (MOGDx), a flexible command line tool for the integration of multi-omic data to perform classification tasks for heterogeneous diseases.
MOGDx incorporates a network taxonomy for data integration and utilises a graph neural network architecture for classification. Networks con be easily integrated, can readily handle missing data, and have been used in a wide variety of biomedical applications in the unsupervised setting. Graph Neural Networks (GNN) have shown powerful classification performance on several benchmark network datasets. The use of GNN's in a supervised setting for disease classification is a promising avenue to redefine heterogenous diseases.
The performance of MOGDx was benchmarked on three distinct datasets from The Cancer Genome Atlas ([TCGA](https://www.cancer.gov/ccg/research/genome-sequencing/tcga)) for breast invasive carcinoma, kidney cancer, and low grade glioma. MOGDx demonstrated state-of-the-art performance and an ability to identify relevant multi-omic markers in each task. It did so while integrating more genomic measures with greater patient coverage compared to other network integrative methods. MOGDx is available to download from [Github](https://github.com/biomedicalinformaticsgroup/MOGDx).For more information find the preprint to our paper online here
-
Network based approach to identify sub-populations within Parkinson's Disease
Barry Ryan (e-mail) is a PhD student from the CDT in Biomedical Artificial Intelligence working in the group on network based approaches in biomedicine, specically aiming to integrate multi-modal data to improve our understanding of neurological disease.

Abstract
Precision medicine is a term coined to describe the movement of medicine towards a personalised preventative approach compared to current reactionary practices. Diseases, individuals and environments are diverse, however current medical practice looks to group together common symptoms under a single disease. Precision medicine seeks to move away from this and identify common causes and manifestations of diseases which pre-date symptoms thus, facilitating preventative treatments. Central to the development of precision medicine is therefore the integration of genetic, environmental and lifestyle data for accurate disease classification.
Networks are all around us. A computer network is a set of computers sharing resources located on network nodes. A social network, such as Facebook or Twitter, is a set of humans sharing information such as photos and posts with each other. A patient similarity network (PSN) is a set of individuals sharing medical information in an attempt to identify commonalities or similarities within a disease. PSN's can be used to integrate multi-modal data sources to classify patients in an interpretable manner (Pai and Bader 2018). In theory, a PSN could be used to; identify novel genetic mutations, improve the understanding of the pathology of disease, improve candidate selection in clinical trials and identify individuals who are at a higher than average risk of a disease.
Parkinson’s disease (PD) is a heterogeneous disease with multiple causes and manifestations many of which remain unknown (Dextera and Jenner 2013). Currently therapies are aimed at relieving symptoms of PD rather than addressing the underlying causes. While genetic causes have been shown to account for 30% of cases, much about the pathology of the disease remains unknown (Klein and Westenberger 2012). Furthermore, common biological pathways between genetic and idiopathic (no known genetic cause) PD only converge late in the disease course. Other previous research has found associations with genetic, environmental and lifestyle factors and PD. For these reasons, PD is a perfect testing ground on which to test a network-based approach for precision medicine.
-
SFARI Genes and How to Find Them
We recently published an article in Scientific Reports based on work by Magdalena that studied the relationship between gene expression profiles of patients with Autism Spectrum Disorders and their status as genes already identified as having a role in the development of ASDs. Put simply, do these genes have expression features that we can learn so that we can build models to identify potential novel ASD causative genes? In this paper we show that, despite the signal being quite weak, there is information that we can leverage from high throughput gene expression studies to give us indications of new genes for ASD. Interestingly, in order to find this signal Magdalena had to integrate gene exrpression profiles across the entire expression landscape by creating weighted gene correlation networks. Only by sharing the information across the whole system was it possible to develop an informative statistical model for candidate prioritisation.
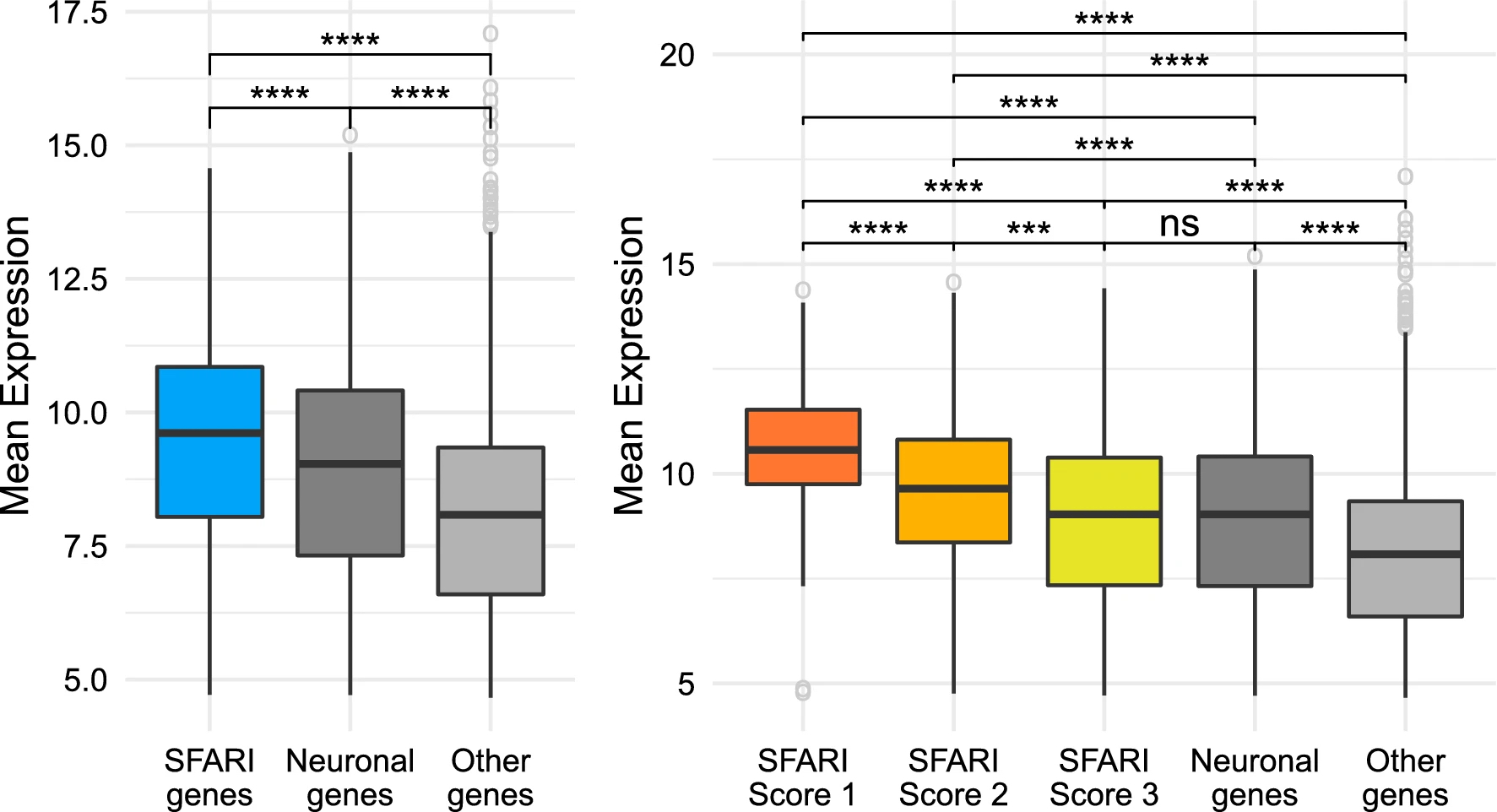
SFARI genes have higher levels of expression than other genes. Comparison between the SFARI genes, genes with neuronal annotations and with the rest of the genes in the dataset. The brackets at the top indicate pairwise comparisons, using a Welch t-test to study wether the differences in level of expression between groups are statistically significant, and the asterisks indicate the magnitude of the corrected p value of each test: ns = p value ≥ 0.05, *p value < 0.5, \*\*p value < 0.01, \*\*\*p value < 0.001, and \*\*\*\*p value < 0.0001. (A) SFARI genes. (B) SFARI Scores. Outlier genes are represented individually as open circles. The t-tests use all the points in each group, including outliers.